- ホーム
- About
About
What’s Project LINKS
Project LINKSとは?
LINKS: Linking Innovation, opeN data, Knowledge, and Solutions
Statement
DATA には不思議なチカラがある。
それは様々な真実を見せてくれる。
データとデータがかけあわさるとき、
今まで見えなかったものが明かされる。
国土交通省では、
直面する様々な社会課題を解決するため、
DATA x DATA のチカラを最大化する
Project LINKS(リンクス)を始動。
LINKS を通じてデータの可能性を引き出し、
新しい価値を創り出します。
POWER of DATA x DATA
Logo
データが活用されることにより、社会がよりよく変わっていく様を「データの拡張性」をイメージしたモチーフによって表現しています。
四角や円のモチーフが、動きながら形を変え、可能性を広げていく、ロゴ自体に拡張性を持たせられる形を目指しています。
サイバー空間を感じさせるネオン調の緑をベースに、類似色の組み合わせにより変化していく過程を感じさせる配色にしています。

ナイチンゲールは
データサイエンティストだった?!
ナイチンゲールは看護師として有名ですが、統計学の先駆者でもありました。
彼女はクリミア戦争の各月の死亡率データを視覚化するため、独自の円グラフ「コックスコームチャート」を考案。これは現代のインフォグラフィックの原型となり、データ可視化の重要性を示しました。
LINKSのロゴマークも、扇状に広がる円弧を表現し、コックスコームチャートのモチーフを取り入れています。
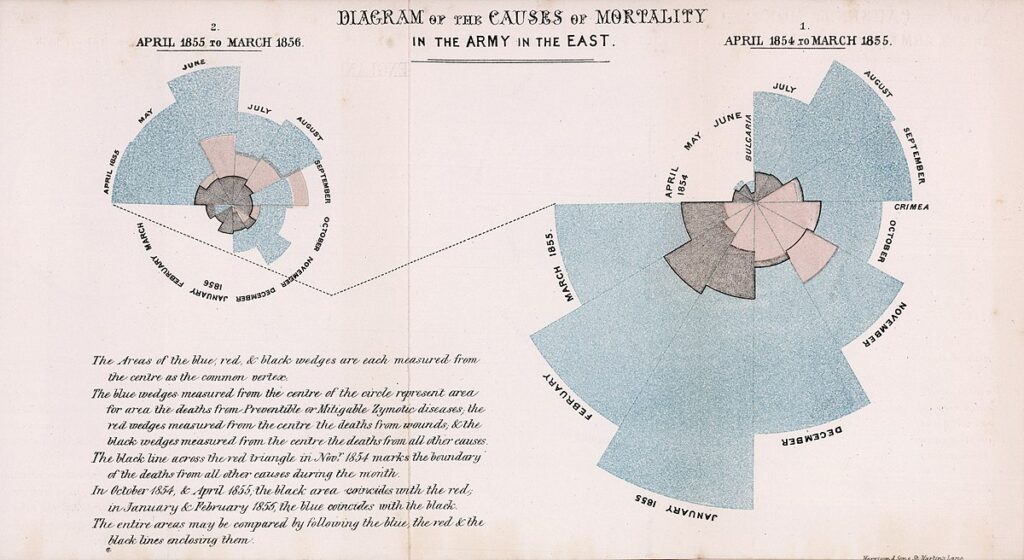
https://commons.wikimedia.org/wiki/File:Nightingale-mortality.jpg
Issue|取組の背景
膨大な行政情報の蓄積
急速に進展する人口減少と少子高齢化は、私たちの社会に大きな影響を与えています。この課題に対応し、防災、交通、まちづくりなど多様な分野における官民の生産性を向上させるためには、政策やビジネスにおけるデータの積極的な活用や、革新的な新サービスの創出が不可欠です。
国土交通省は、幅広い施策・制度・手続を所管する省庁として、膨大な行政情報を蓄積しています。しかし現状では、この貴重な情報資産の多くが利用可能な「データ」として整備されておらず、いわば「宝の持ち腐れ」状態にあります。
Scope|プロジェクトのスコープ
Project LINKSでは、以下の3つのスコープに基づき、取り組みを進めます。
データ整備スキームの確立
・データの拡充国土交通省ではデータ整備スキームの確立に取り組んでいます。具体的には、生成AI(LLM)技術を活用し、Word文書等のデータを機械処理・二次利用可能なデータに自動変換する仕組みの開発を進めています。データ整備が効率化されることにより、国土交通分野の行政情報を使いやすい形で提供し官民が活用できる情報インフラを実現します。
オープン
イノベーション
の推進整備されたオープンデータは、民間企業による革新的なビジネスの創出を促進し、オープン・イノベーションの推進に寄与します。

EBPMの推進
政策立案におけるデータ活用(EBPM)の推進により政策品質を向上し、社会全体の生産性向上に寄与します。
Data management |LINKSのデータ管理
LINKSでは、国土交通省が保有する行政情報をデータ化し、様々なアプリケーションでの可視化を実現するデータ管理システム「LINKS Veda」を構築しています。
■ LINKS Vedaのシステムアーキテクチャ
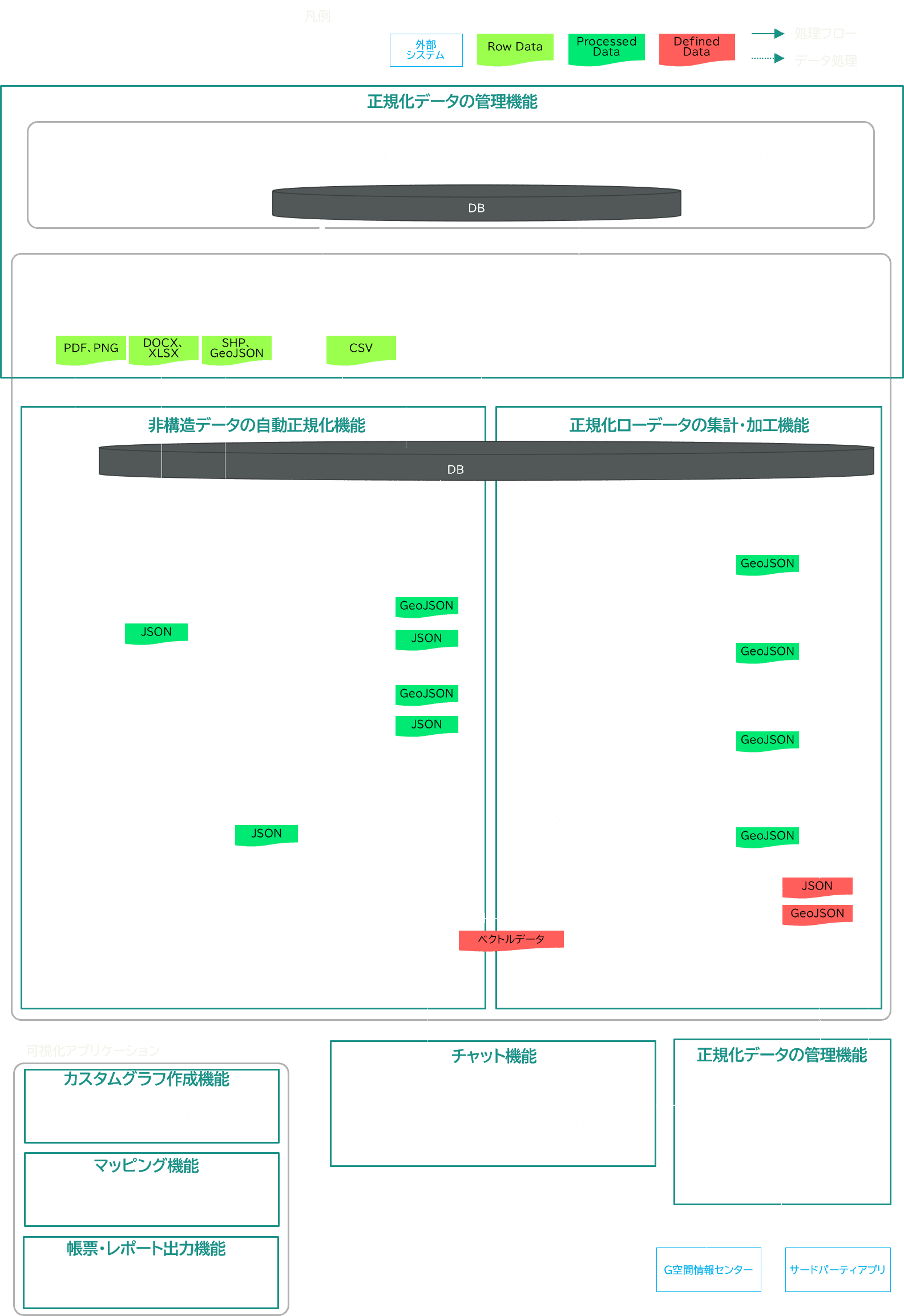
■ LINKS Vedaの技術
LLM (Large Language Model)
- LLM(Large Language Model)は、Transformerと呼ばれる深層ニューラルネットワークアーキテクチャを基盤とした自然言語処理モデルです。
- 膨大な量のテキストデータを学習し、質問応答や翻訳、要約作成、感情分析など幅広いタスクに対応します。
- LLMは、入力された文の全てのトークン間の依存関係をAttention機構を用いて解析し、文脈を正確に理解・生成します。さらに、ベクトル化により文中のトークンとその位置関係を数値化し、特定のドメインにおける知識や専門用語にも対応可能です。
ベクトル解析
- ベクトル解析は、テキストを高次元ベクトル空間に変換し、文脈と意味を数値的に捉えるための前処理です。
- 入力テキストはトークン化され、単語やサブワードに分割されます。その後、各トークンは一意の数値IDに変換されたシーケンスとなり、高次元ベクトルにマッピングされます。これにより、トークンの意味を表現可能となり、言語処理において文脈を考慮しながら単語間の関係を理解し、入力テキストの意味を解析することが可能になります。
構造データ生成モデル
- 構造データ生成モデルは、LLMを活用してPDF、画像、Wordなどの非構造データから情報を抽出し、テーブル形式のデータを自動生成する技術です。
- 画像データの場合には、自動的に画像加工が行われ、 OCRによるテキスト化やレイアウト抽出が行われます。
- ユーザーは構造データのカラム構成やデータ型などのスキーマを指定することで、 対象データ内にある該当の文字データを抽出し、テーブルデータを自動生成することが可能です
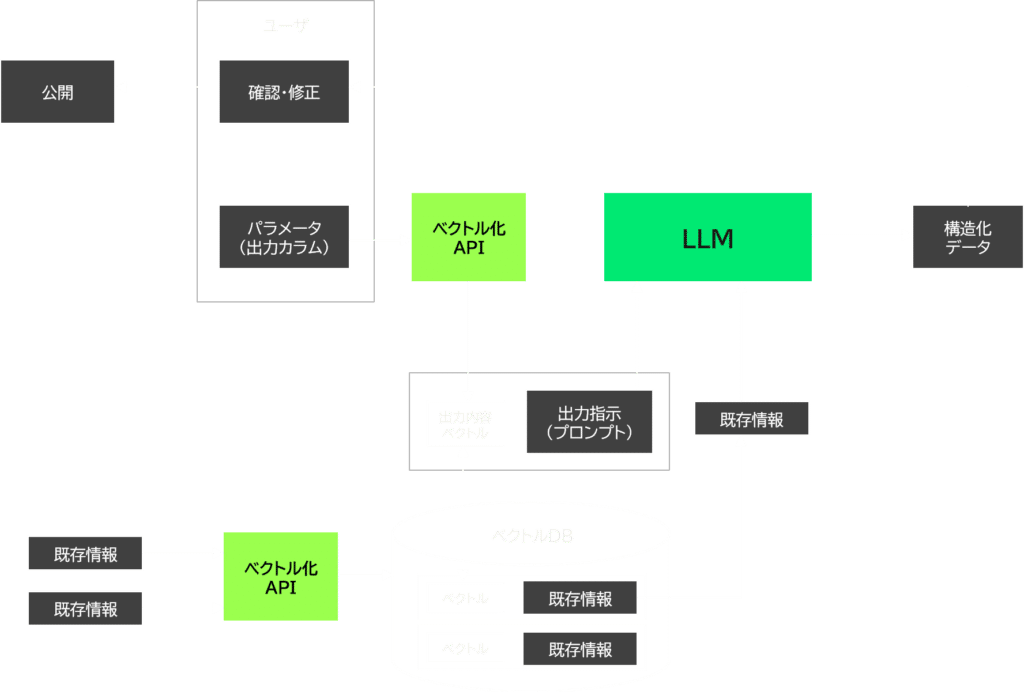
チャット生成
- チャット生成は、ユーザーからの問い合わせに対し、 RAG (Retrieval-Augmented Generation) により適切な返答を提供する技術です。
- ユーザーから入力されたテキストはベクトル解析によりベクトルデータ化され、データ構造化した大量の原票データから生成したベクトルデータベースから関連性の高い情報が検索可能となります。これにより、ユーザーの質問に対する最も適切な情報が抽出され、LLMによって文脈に沿った精度の高い回答を生成すると同時に、出典情報を提示します。
